命令 awk
命令 awk
awk 命令结构
awk -F "," '/^a/ {print $3}' f
-F 部分是参数
’ 内前面是范围,后面是操作
awk 语言的数组下标是从 1 开始的,0 表示整个原始字符串。
详细命令
比如 netstat 命令打印的网络状况如下:
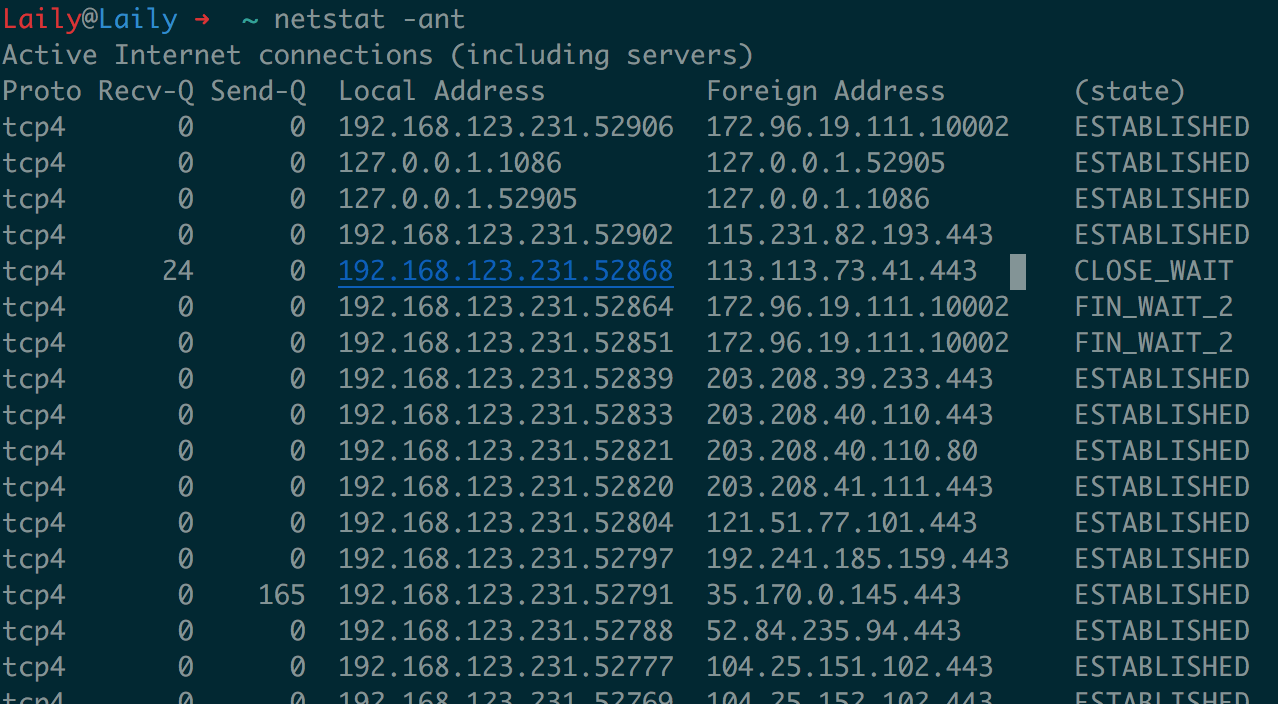
其中第六列显示了网络状态,我们使用 awk 统计一下各网络状态的数目。脚本如下
netstat -ant |
awk ' \\
BEGIN{print "State","Count" } \\
/^tcp/ \\
{ rt[$6]++ } \\
END{ for(i in rt){print i,rt[i]} }'
输出结果如下
LISTEN 14
TIME_WAIT 3
ESTABLISHED 16
从上面可以看出,awk 的命令分为四个部分
-
BEGIN 开头部分,可选。用来设置一些参数,输出一些表头,定义一些变量。
-
END 结尾部分,可选。用来计算一些汇总逻辑,或者输出内容。
-
Pattern 匹配部分,可选,用来匹配一些需要处理的行。
-
Action 部分。主要逻辑体,按行处理。
内置变量
FS 输入内容分隔符
下面两个命令是等价的
awk -F ";" '{print $3}' file
awk 'BEGIN{FS=";"}{print $3}' file
# fs 可以指定多个,比如 FS="[,;|]"
OFS 输出内容分隔符
列数非常多的时候,可以指定输出的分隔符。
awk 'BEGIN{FS=";";OFS="-"}{print $1,$2,$3}' file
NF 列数
awk '{if(NF==3){print}}' file
NR 行号
awk '{print NR,$0}' file
基本命令
# 打印某一列
awk '{print $1}' file
-F 参数可以指定分隔符,比如打印 csv 文件中的第一列和第二列
awk -F "," '{print $1,$2}' file
高级输出
print 语句可以快速而简单的输出,printf 语句则可以按照需要格式化输出。
printf 的语句格式如下
printf(format, value1, value2, ..., valueN)
{printf("total pay for %s is %.2f\\n", $1, $2*$3)}
取出某行某列的元素
$ cat a.txt
a b c
d e f
g h i
$ cat a.txt | awk ''NR==2 {print $3}'
f
Awk 结果存入数组
array=($(ps -ef|grep abc |awk '{print $2}'))
参考
Read other posts