Go pprof 使用
1 概览
pprof 是 Go 提供的一套可视化和分析性能分析数据的工具。 主要包含两部分
-
runtime/pprof 编译进了每个 go 程序
-
go tool pprof 用来分析 profile
Profiling 可以翻译成画像,类似在侦破案件的时候警察会对嫌疑人做的画像。profiling 就是对应用做的画像,描述应用使用 CPU 和内存的情况,用了多少,在哪些地方使用等等。
1.1 profiles 类型
1.1.1 CPU Profiling
CPU profiling 是最常见的 profile 类型,用于报告程序的 CPU 使用情况。 开启 CPU profiling 时,runtime 会每隔 10 ms 中断自己来记录当前 goroutine 的栈踪迹。
一个函数在 profile 里出现的次数越多,说明这个函数占用了越高的执行时间百分比。
1.1.2 Memory Profiling
内存 profiling 在进行对内存分配的时候记录堆内存分配的情况和调用栈信息,不记录栈内存的分配。
和 CPU profiling 一样,内存 profiling 也是基于抽样的方式记录的,默认情况下,每进行 1000 次分配抽样 1 次,这个比例可以更改。
因为内存 profiling 基于抽样,而且它追踪的是已分配的内存(不是使用中的内存,即它也会记录分配了没有使用的内存,比如内存泄露的那部分),所以使用这种方式来确定应用整体的内存使用是不准确的。
1.1.3 Block profiling
阻塞 profiling 是 go 独有的。
阻塞 profile 和 CPU profile 类似,但是它记录的是一个 goroutine 花费在等待共享资源上的总时长。
这对于查找并发竞争瓶颈问题的场景和适合。
阻塞 profiling 可以展示大量的 goroutine 在什么时候被阻塞。
阻塞包括:
-
发送数据到一个没有缓冲的 channel 或者从一个没有缓冲的 channel 接收数据。
-
发送数据到一个满了的 channel 或者从一个空的 channel 里读取数据。
-
加锁失败
阻塞 profiling 是一个针对阻塞的工具,所以在使用前最好先确认瓶颈不在 cpu 和内存。
1.1.4 互斥 profiling
互斥 profiling 和 阻塞 profiling 类似,但是只关注由于互斥竞争导致的延时。
1.2 同一时刻只启用一个 profile
profiling 会对系统性能有明显的影响,特别是修改了内存 profiling 的抽样比例后。 所以在同一时刻最好只启用一个。
2 收集 profile
2.1 工具型应用
如果应用是运行一段时间就结束的,则可以使用 runtime/pprof 库来收集 pprof 信息。
f, err := os.Create(*cpuprofile)
...
pprof.StartCPUProfile(f) // 开始执行 CPU Profiling,f 用于写入结果
defer pprof.StopCPUProfile() // 结束调用
2.2 服务型应用
如果应用是一直运行的,比如 web 型应用,那么可以使用 net/http/pprof 库,它可以提供 HTTP 服务的分析。
如果使用的是默认的 http.DefaultServeMux(通常代码直接使用类似 http.ListenAndServe(“0.0.0.0:8000”,nil),直接添加一行即可
import _ "net/http/pprof"
如果是自定义的 mux,则需要手动注册一些路由(有些 web 框架提供了基础库帮忙注册这些路由,直接调用即可)
r.HandleFunc("/debug/pprof/", pprof.Index)
r.HandleFunc("/debug/pprof/cmdline", pprof.Cmdline)
r.HandleFunc("/debug/pprof/profile", pprof.Profile)
r.HandleFunc("/debug/pprof/symbol", pprof.Symbol)
r.HandleFunc("/debug/pprof/trace", pprof.Trace)
这些方法最终都是在 HTTP 服务上注册了新的 HTTP 接口,访问这些接口即可获得 pprof 信息。
2.3 使用 go tool pprof 命令获取和分析 profile
上面的方法提供了获取 pprof 的方式,文件或者 HTTP 接口,接下来就需要使用 go tool pprof 来获取和分析这些 pprof。
// 文件形式
go tool pprof /path/to/your/profile
// http 形式
go tool pprof http://127.0.0.1/debug/pprof/heap/
上面的命令结束后会提供一个交互终端用来操作分析。
也可以使用 go tool pprof -http=":8081" 这样的 -http 命令来开启一个 http 服务提供 UI 界面操作和分析。
不过生成图片都需要 Graphviz 支持。
3 CPU profile 使用
3.1 模拟一段逻辑
首先写一段读取文本计算单词个数的代码。
package main
import (
"fmt"
"io"
"log"
"os"
"unicode"
)
func readbyte(r io.Reader) (rune, error) {
var buf [1]byte
_, err := r.Read(buf[:])
return rune(buf[0]), err
}
func main() {
f, err := os.Open(os.Args[1])
if err != nil {
log.Fatalf("could not open file %q: %v", os.Args[1], err)
}
words := 0
inword := false
for {
r, err := readbyte(f)
if err == io.EOF {
break
}
if err != nil {
log.Fatalf("could not read file %q: %v", os.Args[1], err)
}
if unicode.IsSpace(r) && inword {
words++
inword = false
}
inword = unicode.IsLetter(r)
}
fmt.Printf("%q: %d words\n", os.Args[1], words)
}
这里也和作者一样,拿《白鲸记》来判断单词数目。
执行一下,得到一下结果。
$ time ./words moby_dick.txt
"moby_dick.txt": 181276 words
./words moby_dick.txt 2.42s user 3.26s system 175% cpu 3.236 total
使用 wc -w 执行对比下
$ time wc -w moby_dick.txt
215830 moby_dick.txt
wc -w moby_dick.txt 0.01s user 0.00s system 89% cpu 0.009 total
统计出来的数目并不一致,因为两份代码判断一个单词是否是单词的方式不一样,不过这无关紧要,两份代码的输入都是整篇文档,而且都是一个个字符去判断的。
接下来查找为什么我们的程序耗时这么久。
3.2 添加 CPU profiling
首先在代码里加上
import (
"github.com/pkg/profile"
)
func main() {
defer profile.Start().Stop()
// ...
接下来运行代码可以看到一个 cpu.profile 文件被创建。
$ ./words moby_dick.txt
2019/07/01 17:12:44 profile: cpu profiling enabled, /var/folders/zv/6mrf40451fd7j_9qh757_w4c0000gn/T/profile458267719/cpu.pprof
"moby_dick.txt": 181276 words
2019/07/01 17:12:47 profile: cpu profiling disabled, /var/folders/zv/6mrf40451fd7j_9qh757_w4c0000gn/T/profile458267719/cpu.pprof
然后使用 go tool pprof 就可以开始分析文件了
go tool pprof /var/folders/zv/6mrf40451fd7j_9qh757_w4c0000gn/T/profile458267719/cpu.pprof
Type: cpu
Time: Jul 1, 2019 at 5:12pm (CST)
Duration: 3.38s, Total samples = 3.74s (110.81%)
Entering interactive mode (type "help" for commands, "o" for options)
(pprof)
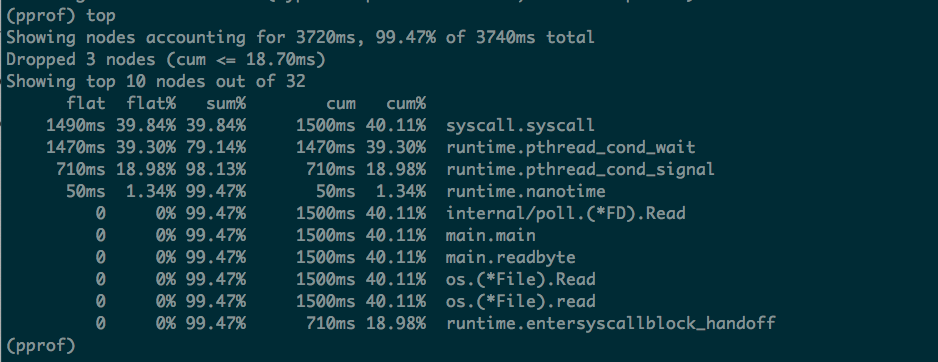
top 将是使用最多的命令,这里可以看到 39.84% 的时间都耗费在 syscall.syscall。
也可以使用 web 子命令,这样可以生成一个可视化的 svg 图片。不过生成图片都需要 Graphviz 支持。
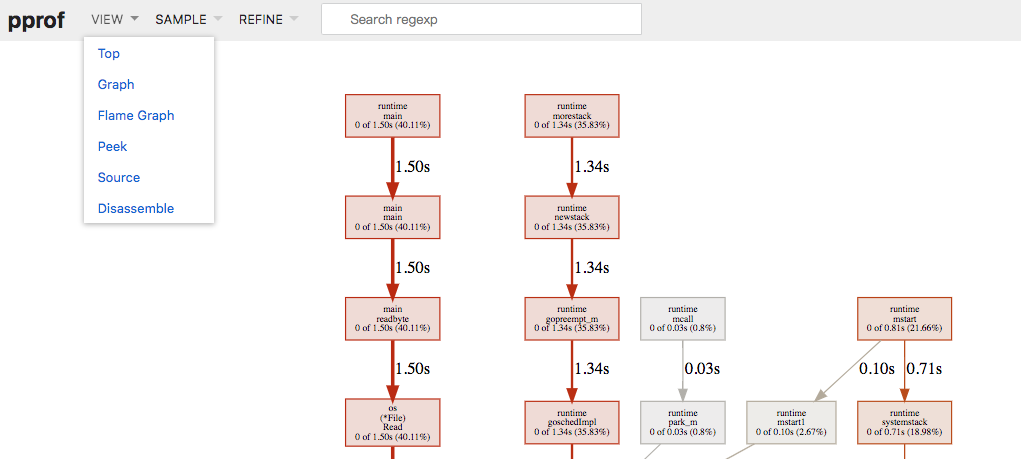
浏览器中有多种视图选择。方格之前表示了调用关系,方格面积越大说明耗时越长。
3.3 改进代码
上面的代码显示耗时最长的是 syscall.Syscall,系统调用的开销是很大的。因为 readbyte 每次调用 syscall.Read 然后读取一个字符,所以输入的内容有多长,就会有多少次系统调用。 然后做如下修改
func main() {
defer profile.Start(profile.MemProfile, profile.MemProfileRate(1)).Stop()
// defer profile.Start(profile.MemProfile).Stop()
f, err := os.Open(os.Args[1])
if err != nil {
log.Fatalf("could not open file %q: %v", os.Args[1], err)
}
b := bufio.NewReader(f)
words := 0
inword := false
for {
r, err := readbyte(b)
if err == io.EOF {
break
}
if err != nil {
log.Fatalf("could not read file %q: %v", os.Args[1], err)
}
if unicode.IsSpace(r) && inword {
words++
inword = false
}
inword = unicode.IsLetter(r)
}
fmt.Printf("%q: %d words\n", os.Args[1], words)
}
然后执行
time ./words moby_dick.txt
2019/07/01 18:04:00 profile: cpu profiling enabled, /var/folders/zv/6mrf40451fd7j_9qh757_w4c0000gn/T/profile219902722/cpu.pprof
"moby_dick.txt": 181276 words
2019/07/01 18:04:01 profile: cpu profiling disabled, /var/folders/zv/6mrf40451fd7j_9qh757_w4c0000gn/T/profile219902722/cpu.pprof
./words moby_dick.txt 0.04s user 0.01s system 21% cpu 0.228 total
4 Memory profile
4.1 模拟内存增长
// 展示内存增长和pprof,并不是泄露
package main
import (
"fmt"
"net/http"
_ "net/http/pprof"
"os"
"time"
)
// 运行一段时间:fatal error: runtime: out of memory
func main() {
// 开启pprof
go func() {
ip := "0.0.0.0:6060"
if err := http.ListenAndServe(ip, nil); err != nil {
fmt.Printf("start pprof failed on %s\n", ip)
os.Exit(1)
}
}()
tick := time.Tick(time.Second / 100)
var buf []byte
for range tick {
buf = append(buf, make([]byte, 1024*1024)...)
}
}
上面的逻辑会定时不断申请内存。接下来我们尝试排查。这里是使用 HTTP 接口方式获取 profile 文件,工具型应用除了采集不一样,后面的排查逻辑是一样的。
4.2 命令行式排查
执行 go tool pprof 命令可以得到下面的输出。
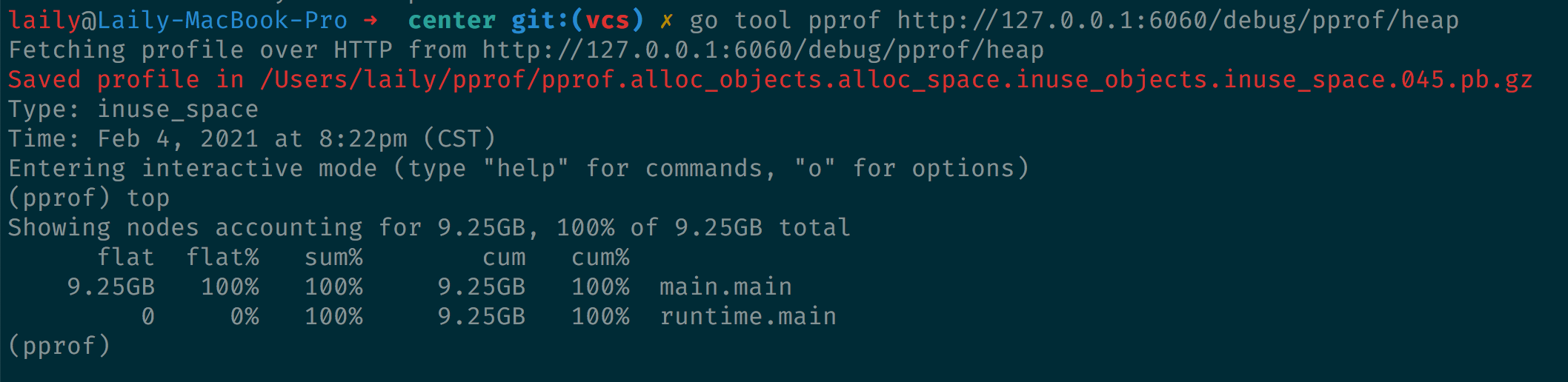
告诉我们 profile 文件被存在了用户目录下的 pprof 目录里。help 可以查看可以支持的命令。
4.2.1 top 命令
Top 命令会按指标大小列出前 10 个函数,比如 CPU 是按执行时间长短,内存是按内存占用多少。
这里我们首先执行 top 命令,显示如上图。top 会列出 5 个统计数据。
-
flat: 本函数占用的内存量
-
flat%: 本函数内存占使用中内存总量的百分比
-
sum%: 前面每一行 flat% 的和
-
cum: 累积量,假如当前函数调用了函数 f,函数 f 占用的内存量也被被记录进来
-
cum%: 和 flat% 类似,是累积量占总量的百分比
4.2.2 traces 命令
打印所有调用栈和调用栈的指标信息。

每一栏分隔是一个调用栈。这里看到不停的出现了 runtime.main 调用 main.main。
4.2.3 list 命令
Traces 之后我们可以发现主要问题出现在 main.main 中。list 命令则是用来帮我们确认函数在代码中的位置。这个命令需要在本地有程序源代码。如果函数没不准确会进行模糊匹配。
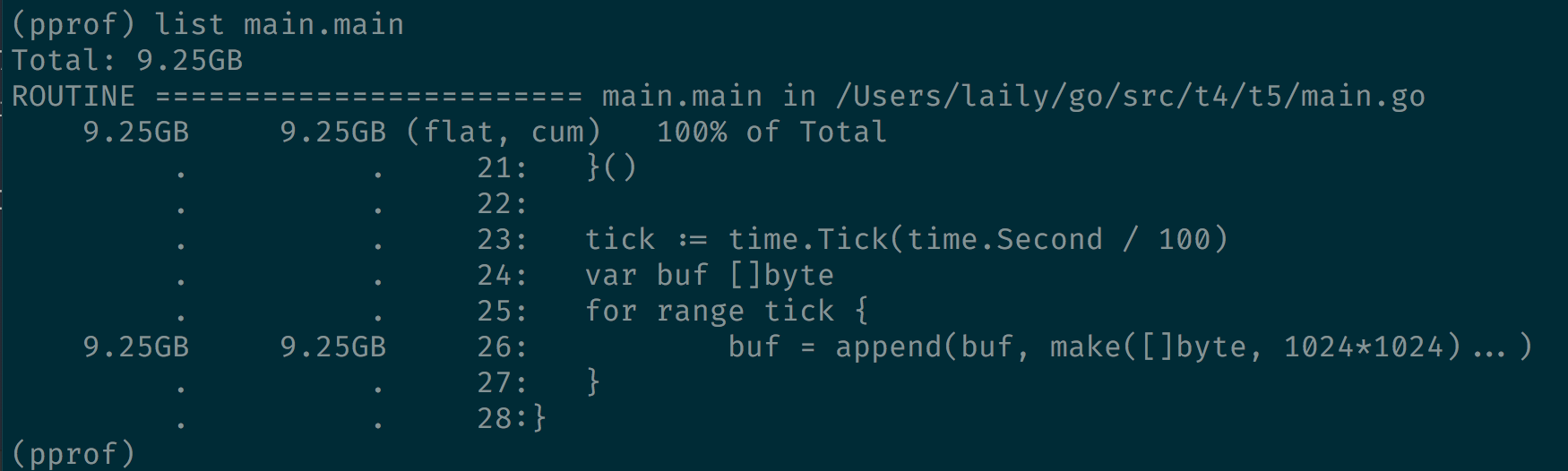
这里已经明确的告知了当前位置申请了大量内存。
4.3 内存 Profile 的局限性
内存 Profile 可以帮助我们发现内存问题,但是不适合查找内存泄露的问题。比如内存主要被哪些代码占用,但是不能说明这是内存泄露。内存泄露是指内存已经不用了但是没有被回收。
举个例子,内存 Profile 展示某段代码 A 申请了大量的内存,但是 A 是一个协程内的逻辑。这就有两种可能,一种是 A 的逻辑有问题导致内存泄露,二是调用 A 的地方逻辑有问题,创建了大量的 A 协程。
所以内存 Profile 没法定位到泄露的原因。
4.3 分配的对象和使用的对象
内存 profiles 有四类,inuse_space, alloc_space, inuse_objects, alloc_objects, 可以根据 go tool pprof 的 flags 指定,也可以在网页端的 SAMPLE 里选择。
alloc 表示已经分配的内存,inuse 表示在使用中的内存。
objects 表示分配的对象个数,space 表示分配的堆内存大小。
这里有个小程序可以验证
const count = 100000
var y []byte
func main() {
defer profile.Start(profile.MemProfile, profile.MemProfileRate(1)).Stop()
y = allocate()
runtime.GC()
}
// allocate allocates count byte slices and returns the first slice allocated.
func allocate() []byte {
var x [][]byte
for i := 0; i < count; i++ {
x = append(x, makeByteSlice())
}
return x[0]
}
// makeByteSlice returns a byte slice of a random length in the range [0, 16384).
func makeByteSlice() []byte {
return make([]byte, rand.Intn(2^14))
}
使用 pprof 在浏览器打开,然藏选择 alloc_objects,就可以看到在 profile 期间引起内存分配的每次调用。
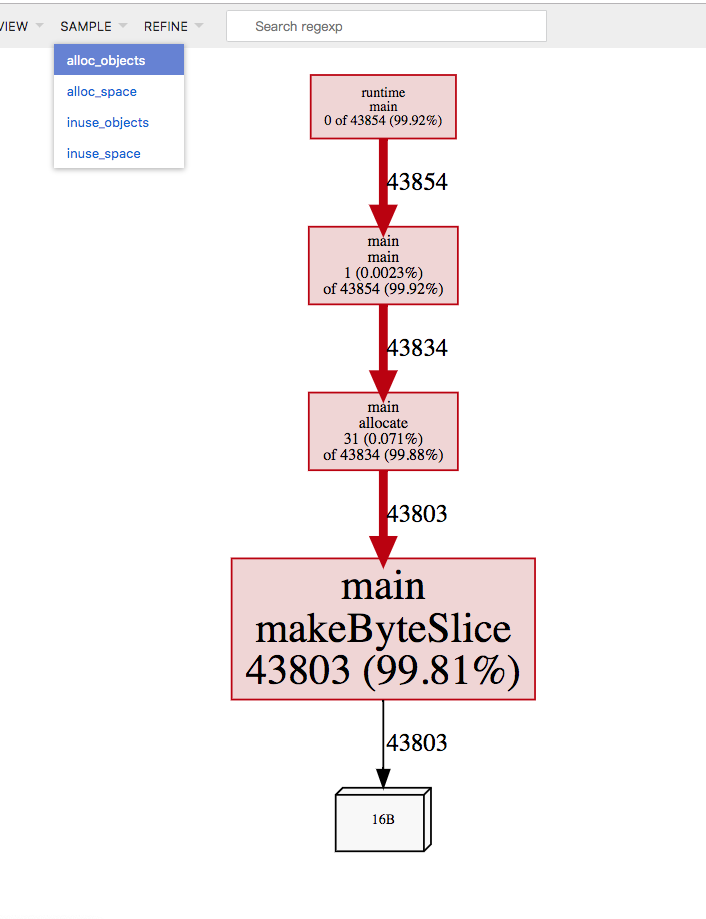
很明显 99% 的内存分配都来自 makeByteSlice。
如果选择 inuse_objects 显示的就是在 profile 期间还在使用的对象。这里缺少了被 gc 回收的栈信息。
5 goroutine 泄露分析
Goroutine 泄露一般都会导致内存泄露。
接下来模拟一个 Goroutine 泄露的逻辑
// goroutine泄露导致内存泄露
package main
import (
"fmt"
"net/http"
_ "net/http/pprof"
"os"
"time"
)
func main() {
// 开启pprof
go func() {
ip := "0.0.0.0:6060"
if err := http.ListenAndServe(ip, nil); err != nil {
fmt.Printf("start pprof failed on %s\n", ip)
os.Exit(1)
}
}()
outCh := make(chan int)
// 死代码,永不读取
go func() {
if false {
<-outCh
}
select {}
}()
// 每s起100个goroutine,goroutine会阻塞,不释放内存
tick := time.Tick(time.Second / 100)
i := 0
for range tick {
i++
fmt.Println(i)
alloc1(outCh)
}
}
func alloc1(outCh chan<- int) {
go alloc2(outCh)
}
func alloc2(outCh chan<- int) {
func() {
defer fmt.Println("alloc-fm exit")
// 分配内存,假用一下
buf := make([]byte, 1024*1024*10)
_ = len(buf)
fmt.Println("alloc done")
outCh <- 0 // 53行
}()
}
5.1 确定是否是 goroutine 泄露
Pprof 支持两个 profile 文件的对比,我们可以隔一段时间获取一次 goroutine 的数量,如果发现一直在持续增长,则极有可能是 goroutine 泄露。
通过 go tool pprof http://localhost:6060/debug/pprof/goroutine 获取多次 profile 文件。
然后执行对比操作
go tool pprof -base
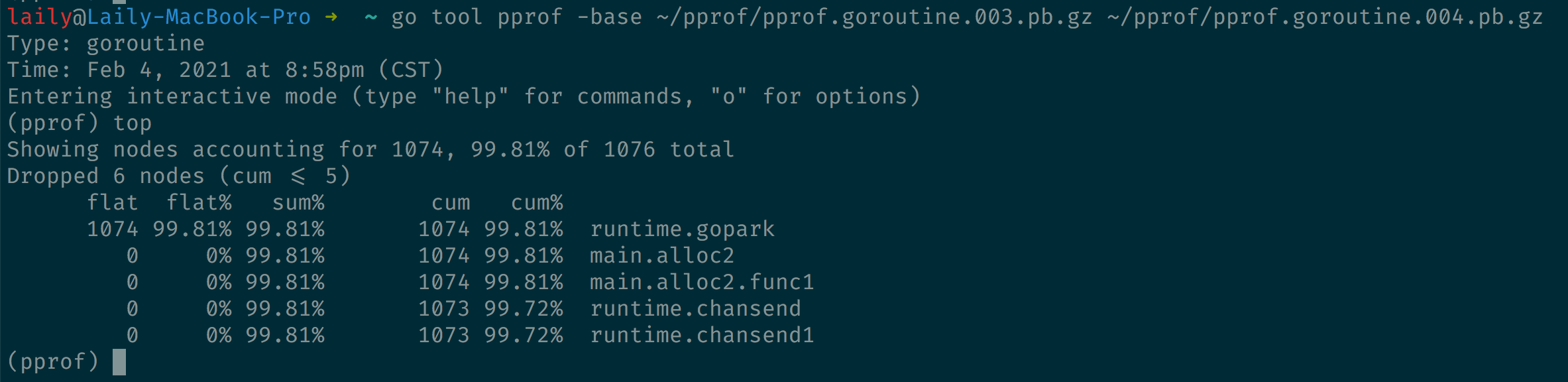
可以看到运行到 runtime.gopark 的 goroutine 数量增加了 1074 个。
单独看第二个 profile 文件,发现有 3259 个 goroutine 挂起(gopark 就是 goroutine 在等待调度)
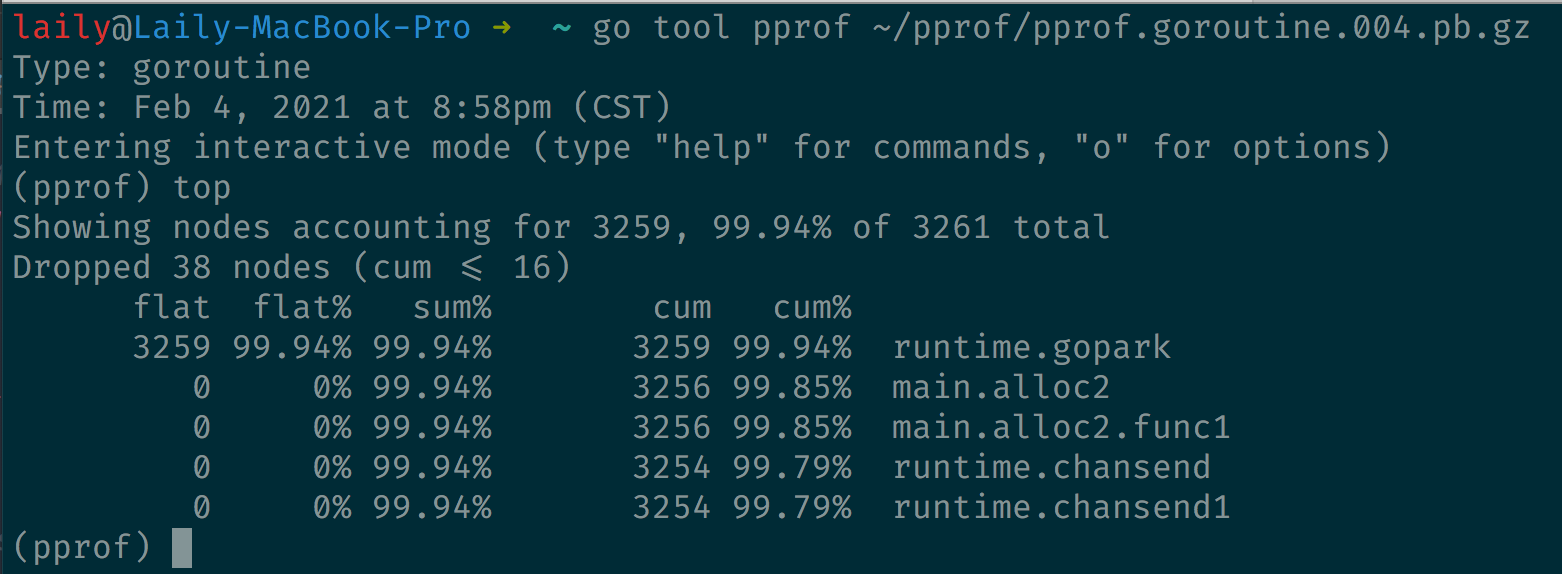
这样有大规模的 goroutine 被挂起,大概率是 goroutine 泄露了。
5.2 定位 goroutine 泄露(命令行方式)
接上面的操作继续排查。
使用 traces 命令,可以列出后者比前者多的 goroutine 的调用栈。
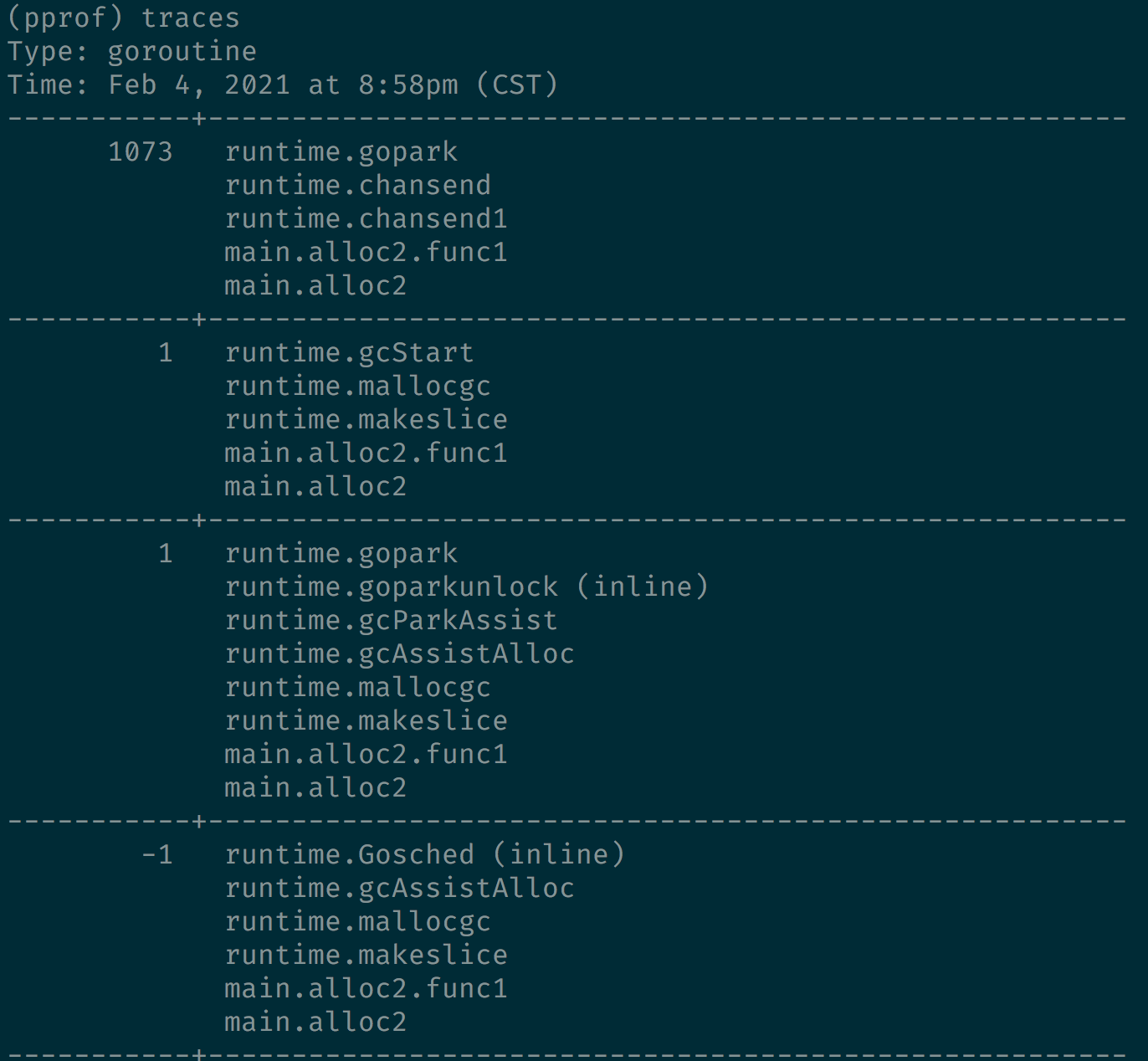
这里发现 1073 个 goroutine 执行过main.alloc2.func1,然后使用 list 查看下代码。
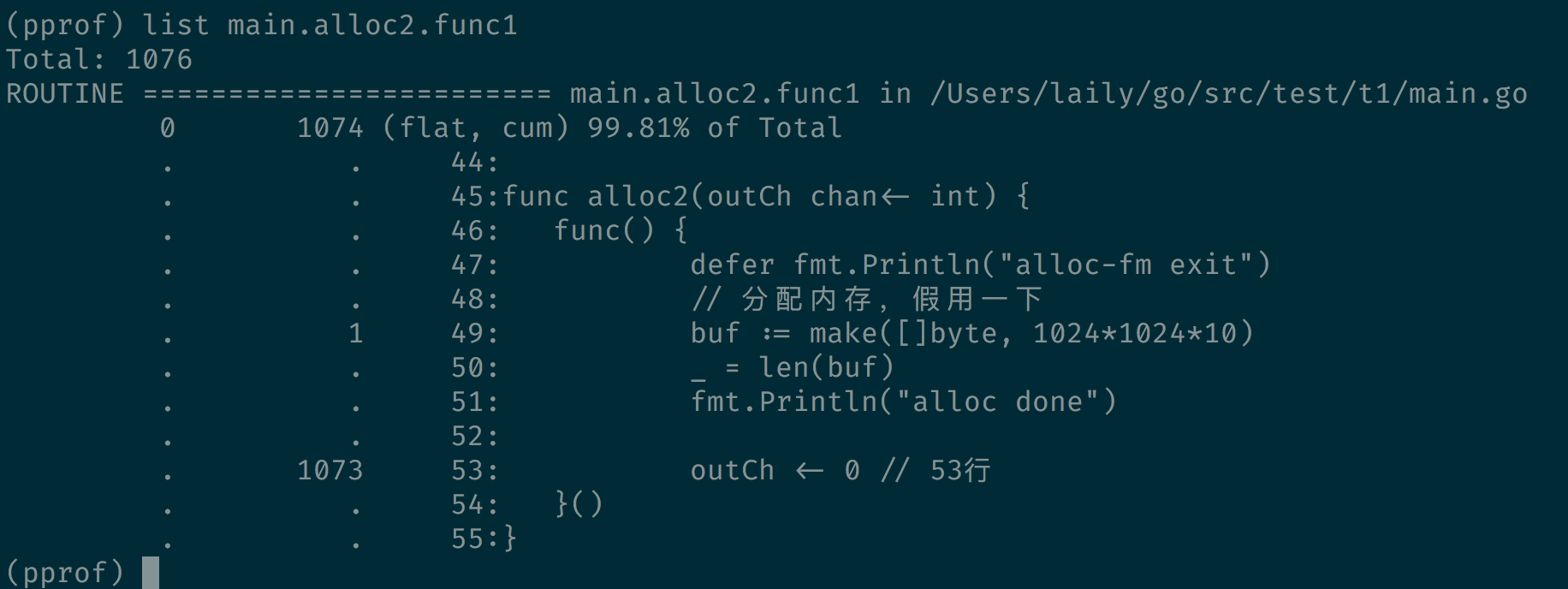
显示 1073 个 goroutine 阻塞在 53 行。
5.3 定位 goroutine 泄露(web 方式)
5.3.1 debug=1 全局查看
访问 http://127.0.0.1:6060/debug/pprof/goroutine?debug=1 (加上了debug=1 的参数,不加就是下载一份 profile 文件)
debug=1 模式可以看到 goroutine 的总数目以及代码各个地方的产生的 goroutine 数目。
会看到一个页面类似下面这样。
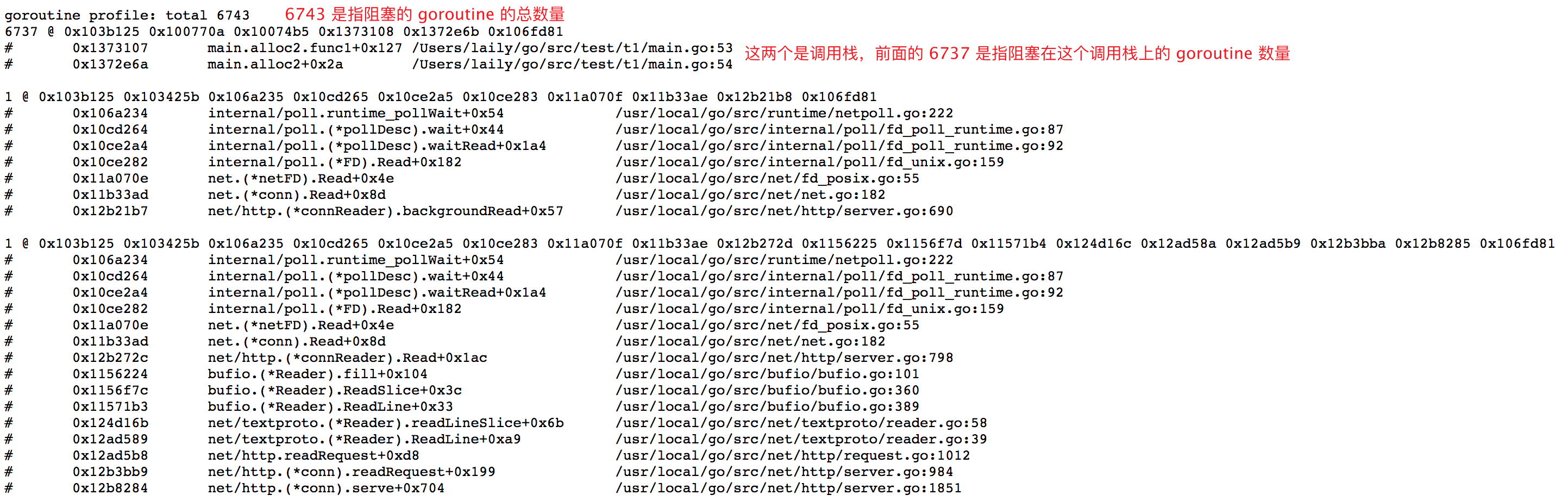
这里就能一眼看到 goroutine 泄露的地方了,数量和文件行数一目了然。
5.3.2 debug=2 单个查看
除了上面的 debug=1 参数,还可以使用 debug=2 参数,debug=2 的模式可以看到每个 goroutine 的信息,它阻塞的原因,阻塞了多久等等。
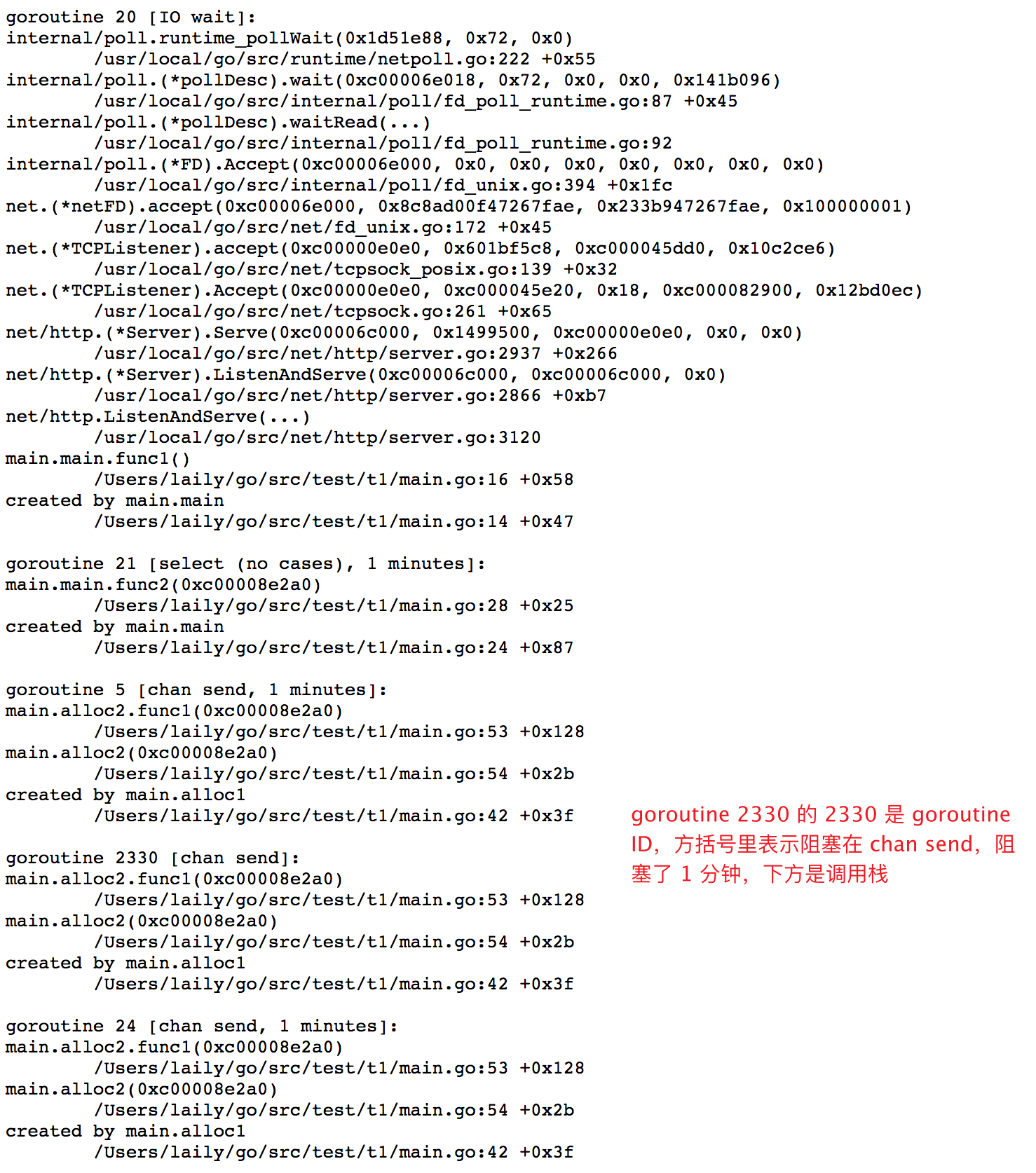
这样也能看到具体出问题的原因,但是一般配合 debug=1 看全局信息,debug=2 看细节更准确。
参考
Performance measurement and profiling
https://cizixs.com/2017/09/11/profiling-golang-program/
https://segmentfault.com/a/1190000019222661?utm_source=tag-newest