同步 Sync
Mutex
type Mutex struct{
state int32 // 表示当前互斥锁的状态
sema uint32 // 控制锁状态的信号量
}
state

state 字段一共 8 个字节,最低三位分别表示三个状态
-
locked: 表示互斥锁的状态
-
woken:表示从正常模式被唤醒
-
starving:当前的互斥锁进入饥饿状态
-
waitersCount: 在当前
互斥锁的公平性
互斥锁可以处于两种操作模式:正常模式和饥饿模式。
在正常模式下,等待者按照先进先出(FIFO)的顺序排队,但是被唤醒的等待者并不拥有互斥锁,而是需要与新到达的goroutine竞争锁的所有权。新到达的goroutine有优势——它们已经在CPU上运行,并且可能有很多,所以被唤醒的等待者很有可能会输掉。在这种情况下,它会被重新排在等待队列的前面。如果等待者尝试获取互斥锁超过1ms都失败了,它就会将互斥锁切换到饥饿模式。
在饥饿模式下,互斥锁的所有权直接从解锁的goroutine交给队列前面的等待者。
新到达的goroutine即使看到互斥锁似乎是解锁的,也不会尝试去获取它,也不会尝试自旋。相反,他们会将自己排在等待队列的尾部。
如果一个等待者接收到了互斥锁的所有权,并且看到要么
(1)它是队列中的最后一个等待者,或者(2)它等待的时间少于1ms,
它会将互斥锁切换回正常操作模式。
正常模式的性能要好得多,因为一个goroutine即使在有等待者被阻塞的情况下也可以连续多次获取互斥锁。
饥饿模式对于防止尾部延迟的病理情况非常重要。
加锁
func (m *Mutex) Lock() {
// 当锁的状态是 0 时,直接将 locked 位置为 1
if atomic.CompareAndSwapInt32(&m.state, 0, mutexLocked) {
return
}
// 否则调用 sync.Mutex.lockSlow 尝试通过自旋等待锁的释放。
m.lockSlow()
}
自旋
在Go语言中,“自旋"是指一个goroutine在尝试获取一个资源(比如互斥锁)时,并不立即进入休眠状态等待资源可用,而是在当前线程上执行一个紧密的循环(即"自旋”),检查锁的状态是否已经释放。
自旋是一种优化策略,目的是在预期锁很快会被释放时避免goroutine的调度开销。如果锁只是被短暂地持有,那么自旋可能会让goroutine更快地获取到锁,因为它省去了在调度器中排队和上下文切换的成本。
自旋可以有效地减少延迟,特别是在锁的争用不是特别激烈的情况下。但是,如果自旋的goroutine长时间获取不到锁,那么它将消耗CPU资源而没有实际的工作完成,这就可能导致性能问题。因此,在实现中会有策略来决定何时开始自旋以及自旋多久。在某些情况下,如果一个goroutine自旋了一段时间后仍然没有获取到锁,它会停止自旋,进入睡眠状态,并将自己放入等待队列中。
因为自旋使用不当会导致对 CPU 的浪费,所以进入自旋的条件很苛刻。
-
互斥锁只有在普通模式才能进入自旋;
-
runtime.sync_runtime_canSpin需要返回true:- 运行在多 CPU 的机器上;
- 当前 Goroutine 为了获取该锁进入自旋的次数小于四次;
- 当前机器上至少存在一个正在运行的处理器 P 并且处理的运行队列为空;
自旋的逻辑执行完后会根据上下文计算当前互斥锁的最新状态,然后使用 CAS 函数 sync/atomic.CompareAndSwapInt32 更新状态并尝试获取锁。
解锁
func (m *Mutex) Unlock() {
new := atomic.AddInt32(&m.state, -mutexLocked)
if new != 0 {
m.unlockSlow(new)
}
}
使用 sync/atomic.AddInt32 函数快速解锁,这时会发生下面的两种情况:
-
如果该函数返回的新状态等于 0,当前 Goroutine 就成功解锁了互斥锁;
-
如果该函数返回的新状态不等于 0,这段代码会调用
sync.Mutex.unlockSlow开始慢速解锁:
sync.Mutex.unlockSlow 会先校验锁状态的合法性 — 如果当前互斥锁已经被解锁过了会直接抛出异常 “sync: unlock of unlocked mutex” 中止当前程序。
在正常情况下会根据当前互斥锁的状态,分别处理正常模式和饥饿模式下的互斥锁:
-
在正常模式下,上述代码会使用如下所示的处理过程:
- 如果互斥锁不存在等待者或者互斥锁的
mutexLocked、mutexStarving、mutexWoken状态不都为 0,那么当前方法可以直接返回,不需要唤醒其他等待者; - 如果互斥锁存在等待者,会通过
sync.runtime_Semrelease唤醒等待者并移交锁的所有权;
- 如果互斥锁不存在等待者或者互斥锁的
-
在饥饿模式下,上述代码会直接调用
sync.runtime_Semrelease将当前锁交给下一个正在尝试获取锁的等待者,等待者被唤醒后会得到锁,在这时互斥锁还不会退出饥饿状态;
RWMutex
结构体
type RWMutex struct {
w Mutex
writerSem uint32 // 写等待读
readerSem uint32 // 读等待写
readerCount int32 // 正在执行读操作的数量
readerWait int32 // 当写操作被阻塞时等待的读操作个数
}
写锁
func (rw *RWMutex) Lock() {
// 加锁阻塞后续的写操作
rw.w.Lock()
// atomic.AddInt32(&rw.readerCount, -rwmutexMaxReaders) 阻塞后续的读操作
// r 是正在执行读操作的数量
r := atomic.AddInt32(&rw.readerCount, -rwmutexMaxReaders) + rwmutexMaxReaders
// 如果仍然有其他 Goroutine 持有互斥锁的读锁,该 Goroutine 会调用 runtime.sync_runtime_SemacquireMutex 进入休眠状态等待所有读锁所有者执行结束后释放 writerSem 信号量将当前协程唤醒;
if r != 0 && atomic.AddInt32(&rw.readerWait, r) != 0 {
runtime_SemacquireMutex(&rw.writerSem, false, 0)
}
}
func (rw *RWMutex) Unlock() {
// 调用 [sync/atomic.AddInt32](https://draveness.me/golang/tree/sync/atomic.AddInt32) 函数将 readerCount 变回正数,释放读锁;
r := atomic.AddInt32(&rw.readerCount, rwmutexMaxReaders)
if r >= rwmutexMaxReaders {
throw("sync: Unlock of unlocked RWMutex")
}
// 通过 for 循环释放所有因为获取读锁而陷入等待的 Goroutine:
for i := 0; i < int(r); i++ {
runtime_Semrelease(&rw.readerSem, false, 0)
}
// 调用 [sync.Mutex.Unlock](https://draveness.me/golang/tree/sync.Mutex.Unlock) 释放写锁;
rw.w.Unlock()
}
读锁
func (rw *RWMutex) RLock() {
// 如果该方法返回负数 — 其他 Goroutine 获得了写锁,当前 Goroutine 就会调用 runtime.sync_runtime_SemacquireMutex 陷入休眠等待锁的释放;
if atomic.AddInt32(&rw.readerCount, 1) < 0 {
runtime_SemacquireMutex(&rw.readerSem, false, 0)
}
}
func (rw *RWMutex) RUnlock() {
// 如果返回值小于零 — 有一个正在执行的写操作,在这时会调用sync.RWMutex.rUnlockSlow 方法;
if r := atomic.AddInt32(&rw.readerCount, -1); r < 0 {
rw.rUnlockSlow(r)
}
// 如果返回值大于等于零 — 读锁直接解锁成功;
}
WaitGroup
结构体
type WaitGroup struct {
noCopy noCopy // 保证 sync.WaitGroup 不会被开发者通过再赋值的方式拷贝;
state1 [3]uint32 // 存储着状态和信号量;
}
sync.noCopy 是一个特殊的私有结构体,tools/go/analysis/passes/copylock 包中的分析器会在编译期间检查被拷贝的变量中是否包含 sync.noCopy 或者实现了 Lock 和 Unlock 方法,如果包含该结构体或者实现了对应的方法就会报错。
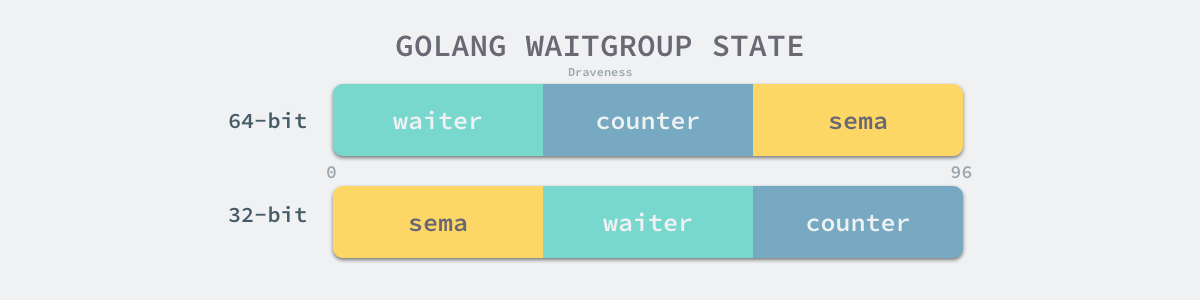
state1
// 64-bit value: high 32 bits are counter, low 32 bits are waiter count.
// 64-bit atomic operations require 64-bit alignment, but 32-bit
// compilers do not ensure it. So we allocate 12 bytes and then use
// the aligned 8 bytes in them as state, and the other 4 as storage
// for the sema.
[3]uint32 一共 96 位。高 32 位是计数器,低 32 位是等待的协程数量。中间用 12 字节存储其它数据。
关于内存对齐
内存对齐
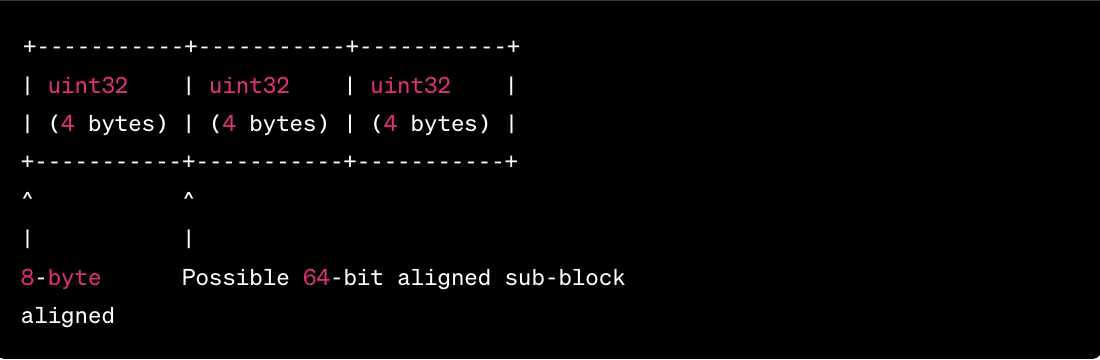
32 位的编译器会将地址的起始位置分配在 4 的倍数上来保证内存对齐。但是在 64 位的系统上运行的时候必须是 8 的倍数的起始地址才行。
如上图,假设左侧为低地址,我们真正需要保证原子操作的后面的 4 个字节,
Add
func (wg *WaitGroup) Add(delta int) {
statep, semap := wg.state()
state := atomic.AddUint64(statep, uint64(delta)<<32)
v := int32(state >> 32)
w := uint32(state)
if v < 0 {
panic("sync: negative WaitGroup counter")
}
if v > 0 || w == 0 {
return
}
*statep = 0
for ; w != 0; w-- {
runtime_Semrelease(semap, false, 0)
}
}
参考
https://draveness.me/golang/docs/part3-runtime/ch06-concurrency/golang-sync-primitives/