HTTP2 介绍
为什么我们需要 HTTP/2
- 解决 HTTP/1.1 的队头阻塞问题(传输效率问题)
- 降低传输流量
- 真正的支持多路复用
HTTP/2 的优点
HTTP/2 源自 SPDY/2
- HTTP/2 采用二进制格式传输数据(HTTP/1.x 采用文本格式)。
二进制协议的解析效率高,几乎没有解析代价。
二进制协议没有冗余字段,占用带宽少。
压缩及 https 技术弱化了文本协议的价值。
- HTTP/2 对消息头采用 HPACK 进行压缩传输,能够节省消息头占用的网络流量。
- 多路复用。简答来说就是所有请求都通过一个 TCP 连接并发完成。HTTP/1.x 的 pipeline 技术也能并发发送请求,但是多个请求之间的响应是会被阻塞的。
- Server Push。服务端能够快速的把资源推送给客户端。比如可以主动把 js 和 css 文件推送给客户端,而不同等客户端解析完 html 后再请求这些数据。
HTTP/2 的缺点
- 单连接开销比较大。HPACK 数据压缩算法会更新两端的索引表。这样让连接有了状态,破坏状态就要重建查找表。单连接占用内存比较多。
- 有些场景可能不需要 SSL。如果数据不需要维护,或者已经使用其他编码进行保护了,那强制 TLS 就没有必要了。
- 需要抛弃针对 HTTP/1.x 的优化。
HTTP/2 的基石 - Frame
Frame 技术是 HTTP/2 二进制格式的基础,它就类似 tcp 里的数据包一样。HTTP/2 之所以能有如此多的特性,正式因为底层数据格式的改变。
Frame 的基本格式如下
+-----------------------------------------------+
| Length (24) |
+---------------+---------------+---------------+
| Type (8) | Flags (8) |
+-+-------------+---------------+-------------------+
|R| Stream Identifier (31) |
+=+=================================================+
| Frame Payload (0...) ...
+---------------------------------------------------+
Length: 表示 Frame Payload 的长度,另外 Frame Header 的长度是固定的 9 字节,Length + Type + R + Stream Identifier = 72 bit。
Type: 区分这个 Frame Payload 存储的数据属于 HTTP Header 还是 HTTP Body;另外 HTTP/2 新定义了一些其他的 Frame Type。例如 0 表示 DATA 类型(即 HTTP/1.x 里的 Body 部分的数据)
Flags:共 8 位,每位都起标记作用。每种不同的 Frame Type 都有不同的 Frame Flags。例如发送最后一个 DATA 类型的 Frame 时,就会将 Flags 的最后一位设置为 1 (flags &= 0x01),表示 END_STREAM,说明这个 Frame 时流的最后一个数据包。
R:保留位。
Stream Identifier: 流 ID,当客户端和服务端建立 TCP 连接时,就会发送一个 Stream ID = 0 的流,用来做初始化的工作。之后客户端和服务器端从 1 开始发送请求和响应。
Frame 由 Frame Header 和 Frame Payload 两部分组成。不论是原来的 HTTP Header 还是 HTTP Body,在 HTTP/2 中,都将这些数据存储到 Frame Payload,组成一个个 Frame,再发送请求/响应。通过 Frame Header 中的 Type 区分这个 Frame 的类型。
HTTP/1.x 和 HTTP2 的转换图如下
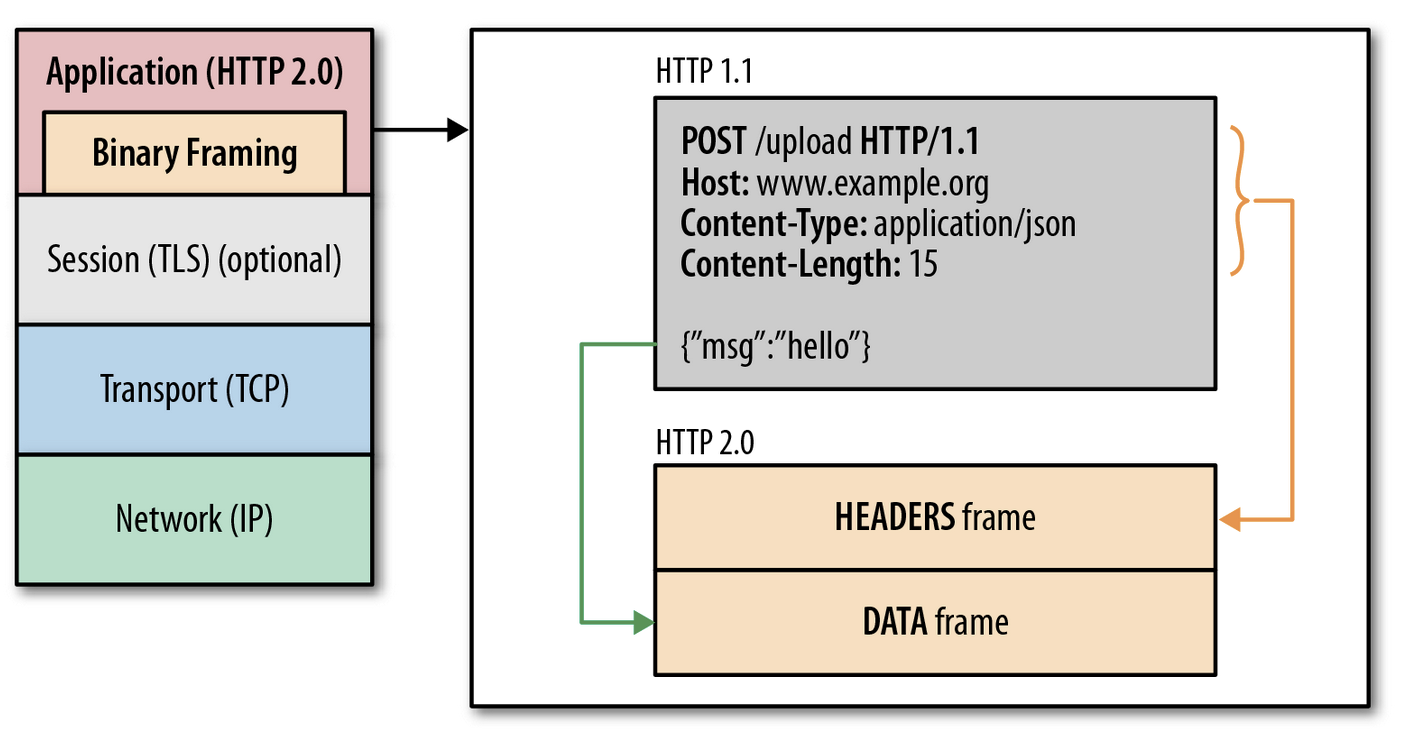
头部压缩
HTTP/2 专门设计了 HPACK 头部压缩技术。
这个方式使用一个索引表来定义常用的 HTTP Header,请求的时候直接用索引位置即可。例如 :method=GET 使用索引值 2 表示,:path=/index.html 使用索引值 5 表示。完整的索引列表参考 HPACK Static Table。这样只要给服务器发送一个 Frame,该 Frame 的 Payload 部分存储 0x8285,Frame Type 设置为 Header 类型,那么就表示请求的内容是 GET /index.html。
为什么是 0x8285 而不是 0x0205,这里高位设置为 1 表示这个字节是一个完全索引值(key 和 value 都在索引中)。
因为索引表的大小是有限的,它仅保存了一些常用的 HTTP Header,同时每次请求还可以在表的末尾动态追加新的 HTTP Header 缓存。动态增加的部分称之为 Dynamic Table。Static Table 和 Dyanamic Table 在一起组合就成了索引表。
<---------- Index Address Space ---------->
<-- Static Table --> <-- Dynamic Table -->
+---+-----------+---+ +---+-----------+---+
| 1 | ... | s | |s+1| ... |s+k|
+---+-----------+---+ +---+-----------+---+
^ |
| V
Insertion Point Dropping Point
HPACK 不仅仅通过索引键值对来降低数据量,同时还会将字符串使用霍夫曼编码来压缩字符串大小。
以常用的 User-Agent 为例,它在静态表中的索引值是 58,它的值是不存在的,因为它的值是多变的。第一次请求的时候它的 key 用 58 表示,表示这是一个 User-Agent,它的值部分会进行霍夫曼编码(如果编码后的字符串变长了,则不采用霍夫曼编码)。服务端收到请求后,会将这个 User-Agent 添加到动态表里缓存起来,分配一个新的索引值,假如是 62。客户端下一次请求时,只需要发送 0xBE (同样高位为 1),便可以代表: User-Agent:Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/33.0.1750.146 Safari/537.36。其过程如下图所示:
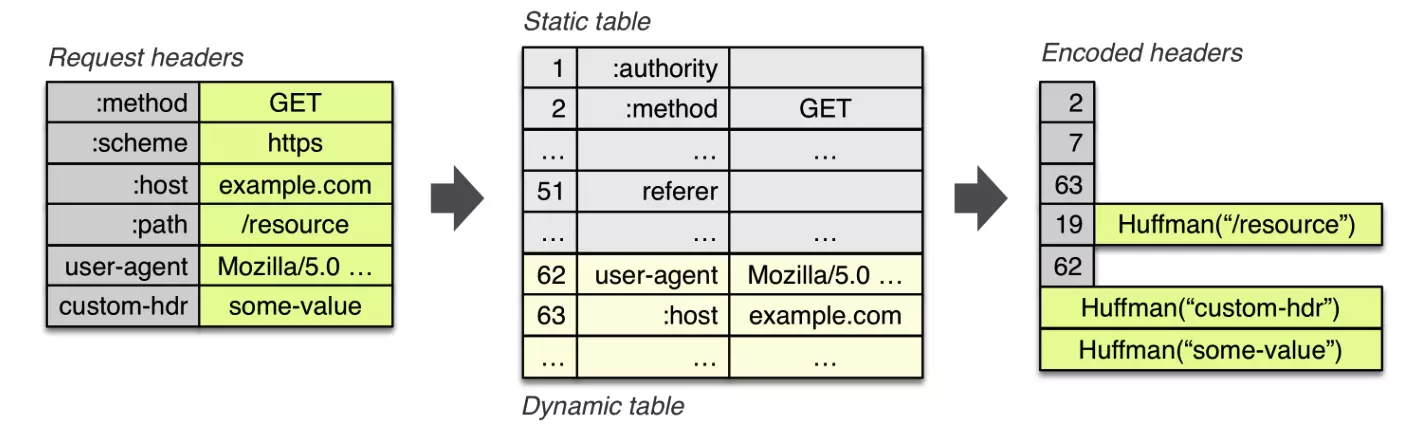
Multipexing 多路复用
每个 Frame Header 里都有一个 Stream ID,每次请求/响应都使用不同的 Stream ID。就像同一个 TCP 连接上的数据包通过 IP:PORT 来区分数据包去往哪里一样。通过 Stream ID 标识,所有的请求和响应就可以同时跑在一条 TCP 连接上了。根据 Stream ID 就可以找到一组对应的请求/响应。
下图是 http, spdy 的并发模型对比(http2 和 spdy 是类似的)
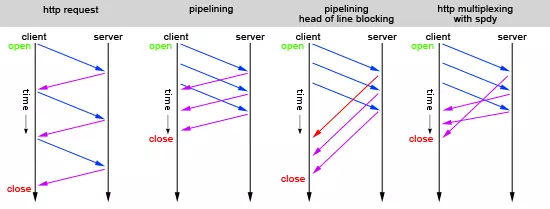
当流并发时,会涉及到流的优先级和依赖。优先级高的流会被优先发送。
图片请求的优先级要低于 CSS 和 SCRIPT。
Server Push
当服务器需要主动推送某个资源时,便会发送一个 Frame Type 为 PUSH_PROMISE 的 Frame,里面呆了 PUSH 需要新建的 Stream ID。意思是告诉客户端,接下来我要用这个 ID 向你发送东西,客户端准备好接收。
客户端解析 Frame 时,发现它是一个 PUSH_PROMISE 类型,便会准备接收服务器要推送的流。